
如何在 Linux 中使用 Netdata 监控 MySQL 或 MariaDB
Netdata 是一款免费、开源、简单且可扩展的实时系统性能和健康状况监控应用程序,适用于 Linux、FreeBSD 和 MacOS 等类 Unix 系统。
它收集各种指标并将其可视化,使您可以观察系统上的操作。它支持各种插件来监控当前系统状态、运行的应用程序和服务,例如MySQL数据库服务器等等。
在本文中,我们将解释如何在基于 RHEL 的发行版上使用 Netdata 监控 MySQL 数据库服务器性能。
在本文结束时,您将能够从网络数据监控网络观看 MySQL 数据库服务器的带宽、查询、处理程序、锁定、问题、临时数据、连接、二进制日志、线程指标的可视化界面。
第1步:在Linux中安装MySQL数据库服务器
如果您的基于 RHEL 的发行版上没有安装 MySQL 或 MariaDB,您可以在设置 Netdata 之前轻松安装其中之一。监控。
安装MySQL数据库服务器
sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el9-1.noarch.rpm
sudo yum install mysql-community-server -y
sudo systemctl start mysqld
sudo systemctl enable mysqld
sudo grep 'temporary password' /var/log/mysqld.log
sudo mysql_secure_installation
安装 MariaDB 数据库服务器
sudo yum install mariadb-server -y
sudo systemctl start mariadb
sudo systemctl enable mariadb
sudo mysql_secure_installation
要从 MySQL/MariaDB 数据库服务器收集性能统计信息,netdata 需要连接到数据库服务器。因此,创建一个名为“netdata”的数据库用户,使其能够连接到本地主机上的数据库服务器,而无需密码。
mysql -u root -p
CREATE USER 'netdata'@'localhost';
GRANT USAGE on *.* to 'netdata'@'localhost';
FLUSH PRIVILEGES;
exit;
步骤2:安装Netdata来监控MySQL性能
幸运的是,我们已经有了 netdata 开发人员提供的单行启动脚本,可以轻松地从 github 存储库上的源代码树安装它。
kickstarter 脚本会下载另一个脚本来检测您的 Linux 发行版;安装构建网络数据所需的系统包;然后下载最新的netdata源树;在您的系统上构建并安装它。
此命令将帮助您启动 kickstarter 脚本,并允许安装所有 netdata 插件所需的软件包,包括 MySQL/MariaDB 的插件。
wget -O /tmp/netdata-kickstart.sh https://get.netdata.cloud/kickstart.sh && sh /tmp/netdata-kickstart.sh
如果您不是以 root 身份管理系统,系统将提示您输入 sudo 命令的用户密码,并且还会要求您确认一些功能只需按[Enter]即可。
脚本完成构建和安装 netdata 后,您可以启动 netdata 服务并使其在系统引导时启动。
sudo systemctl start netdata
sudo systemctl enable netdata
Netdata 默认侦听端口 19999,您将使用此端口访问 Web UI。因此,请打开系统防火墙上的端口。
sudo firewall-cmd --permanent --add-port=19999/tcp
sudo firewall-cmd --reload
步骤3:配置Netdata来监控MySQL/MariaDB
默认配置足以让您开始监控 MySQL/MariaDB 数据库服务器。如果您已阅读文档并对上述文件进行了任何更改,则需要重新启动 netdata 服务才能使更改生效。
sudo systemctl restart netdata
接下来,打开 Web 浏览器并使用以下任意 URL 访问 netdata Web UI。
http://domain_name:19999
OR
http://SERVER_IP:19999
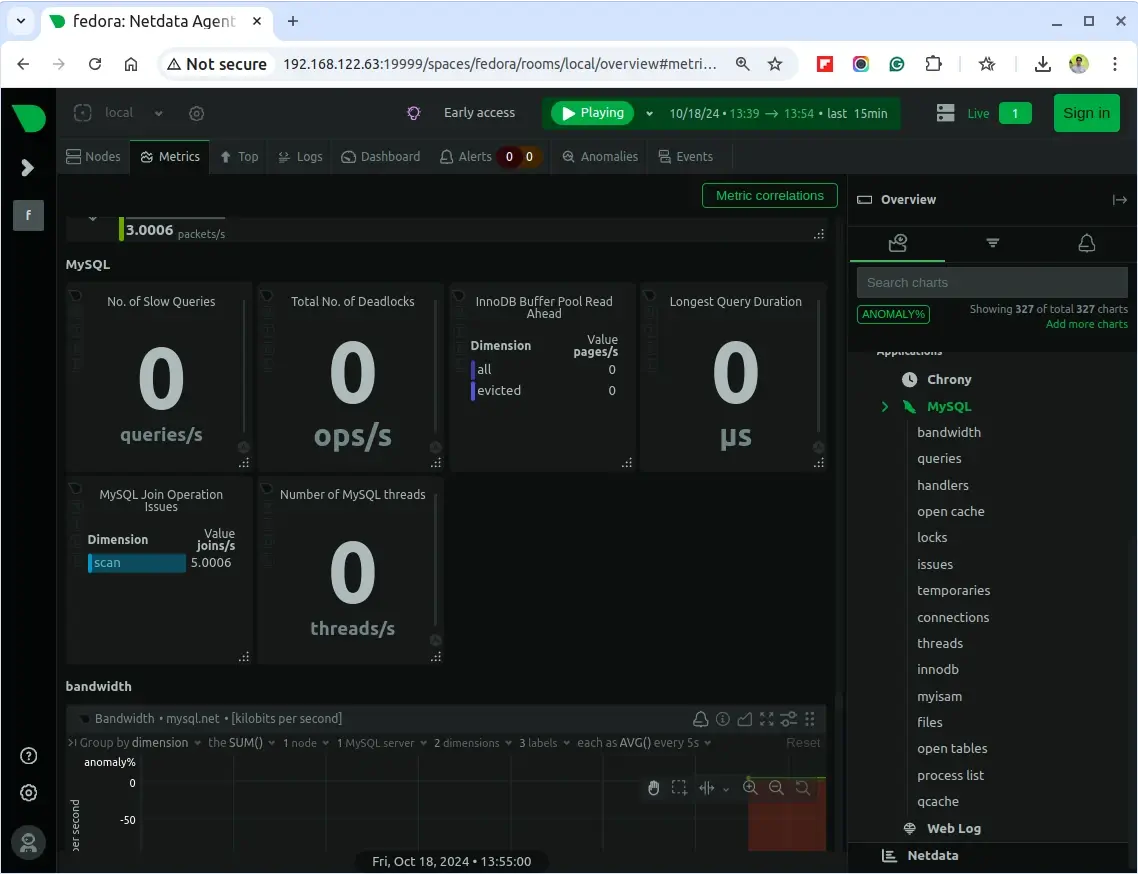
在 netdata 仪表板中,在右侧插件列表中搜索“MySQL local”,然后单击它开始监控您的 MySQL/MariaDB 服务器。您将能够观看带宽、查询、处理程序、锁以及 galera 的可视化效果,如以下屏幕截图所示。
Netdata Github 存储库:https://github.com/netdata/netdata
就这样!在本文中,我们解释了如何在基于 RedHat 的系统上使用 Netdata 监控 MySQL/MariaDB 数据库服务器性能。使用下面的评论表提出问题或与我们分享其他想法。